So the coding period of GSoC 2013 is officially over, and I want to talk about how far Beeswarm has come in the last five months. I think the best way to explain my work is by introducing and explaining the Beeswarm terminology first.
What exactly is Beeswarm?
Simply put, Beeswarm is a special honeypot, with a system of automated clients, which use that honeypot. Information about attackers is gathered by analyzing the difference between the expected and actual traffic at the server end of the honeypot.
In technical terms, Beeswarm is a Honeytoken project, that aims to use client side traffic as the Honeytoken. It consists of three major components:
- Hive
The Hive is the actual Honeypot server. It runs on gevent and supports multiple protocols such as Telnet, SSH, SMTP, FTP, etc. It can also be used as a standalone Honeypot in the traditional way (without the other two components).
- Feeder
Essentially, the Feeder is the client part of Beeswarm. The job of the Feeder is to actively attract attackers to the Honeypot (Hive). It runs client sessions on the remote Hive server. These clients are "semi-intelligent". By "semi-intelligent", I mean that they have a rudimentary intelligence which allows them to login to the different Hive servers, and perform legitimate actions on them. For example, the FTP Feeder logs into the server (Hive), lists the files, and then either downloads or deletes them.
- Beekeeper
The Beekeeper is the Web based management interface for Beeswarm. It analyzies and classifies the client sessions that are made on the Hive. In fact, one of its most important tasks is to correlate the data from Hive and Feeder, and determine if a particular session was from a malicious attacker. Beekeeper allows easy deployment of Hives and Feeders by providing customized bootable ISOs for them.
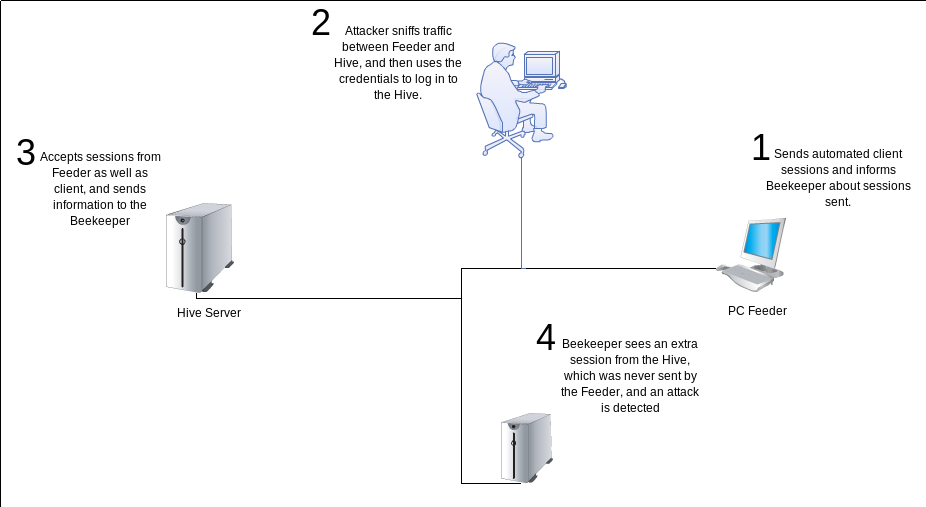
A simple use case, where one could detect MITM attacks:
Through the course of the last five months, a lot of progress has been made in the following areas:
- Interactivity of Hive capabilities
- The Beekeeper web-interface
- Intelligence of the automated Feeder clients
- Deployment
I'll give a brief update on each of these areas, focusing on the new things, and places where creative ideas are used, which could also be beneficial outside of this particular project.
Interactivity of Hive Protocols
This is the part of the project that I enjoyed working on the most. As mentioned in my previous posts, the Hive now has very interactive SSH and Telnet capabilities. It also boasts a fully functional SMTP server, that can capture emails being sent. The FTP capability too is largely functional, although it is probably not completely standards-compliant. It does, however, play along nicely with most FTP clients. The HTTP and HTTPs capabilities too, serve real pages from a directory. This means that it is quite possible to emulate devices like routers, which usually have a very simple web-ui.
The Beekeeper Web Interface
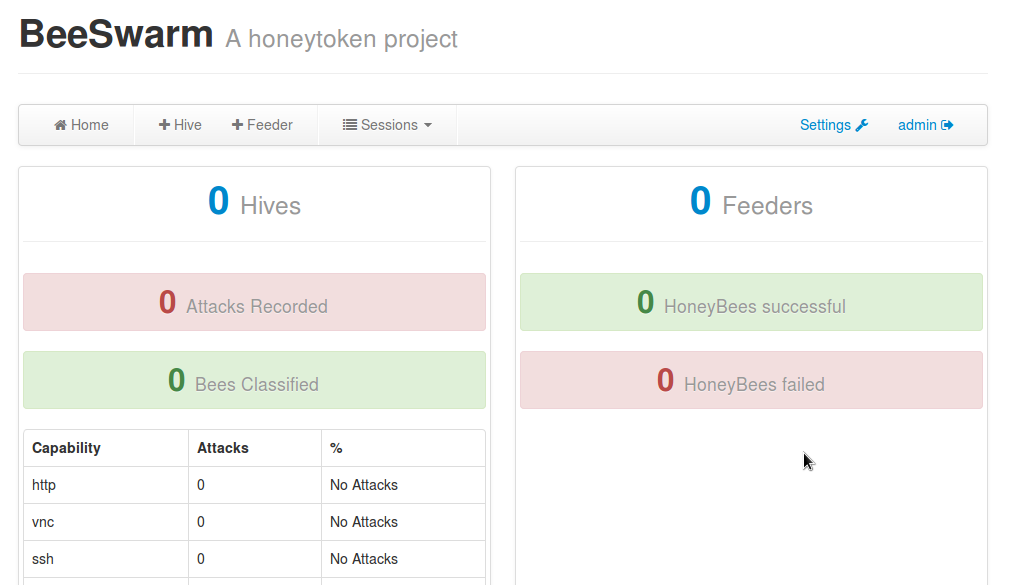
Beekeeper is the management and information processing part of Beeswarm. It is built on top of Flask, and Twitter Bootstrap. It allows administrators to view the current status, add new Hives/Feeders, and download bootable ISO files for them. Here are a few screenshots of the Beekeeper, in action:
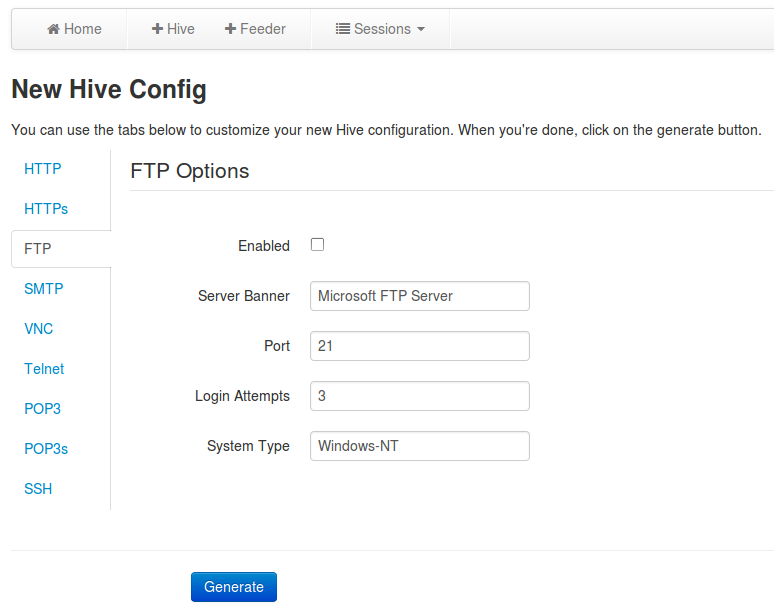
The next screenshot shows the webpage for configuring a new Hive instance. The various tabs allow one to customize the different protocols offered by the Hive instance.
Apart from the management tasks, Beekeeper also does the job of classifying the sessions done on the Hive, and maintaining the database.
Intelligence of automated Feeder clients
I'll keep this section short, since this is already discussed in my previous blog posts. I think a small summary will be useful though:
- FTP
- The client lists the files, and randomly downloads a few of them. It also sends FTP commands such as SYST, in order more accurately emulate real clients.
- HTTP(s)
- The HTTP(s) clients extract the links from the root document (/index.html) and start visiting them. They stop after a randomly generated depth is reached.
- POP3(s)
- The POP3(s) clients retrieve the list of available emails, and then deletes them all, one by one. This is exactly what some mail clients do.
- SMTP
- The SMTP client chooses a few emails from the spam corpus that comes with Beeswarm, and sends a random number of them to the Hive SMTP capability.
- SSH/Telnet
- These are more complicated than the previous examples. They use a number of methods to act intelligently, as explained in my previous blog posts.
Deployment
The deployment of new Hives and Feeders has become much easier, since Beeswarm now has the ability to generate customized bootable ISO files for each of them. The ISOs are basically generated using Debian Live. A very interesting approach was suggested by my mentor to reduce the time required for ISO generation. It goes something like this:
- Generate a "Base" ISO, which has a dummy tarball file embedded into it. This file is filled with a specific pattern (I chose a series of '0x07' bytes).
- Whenever a new custom ISO is required, find and overwrite the special pattern mentioned above, with an actual tar file.
- Use it inside the ISO after boot.
This brought down the time for ISO generation from about 20 minutes to around 13 seconds.
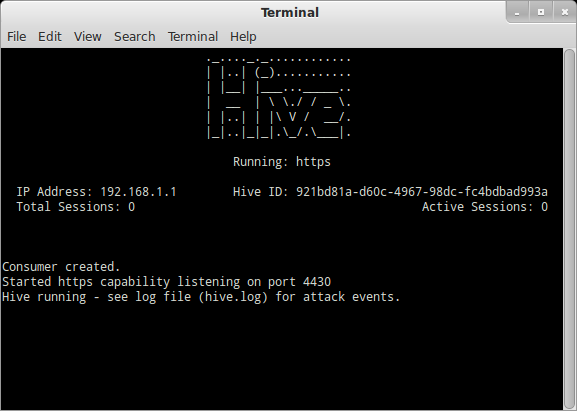
In order to view status easily on the bootable ISOs, I also added a Curses based UI to Beeswarm. It's a simple status screen, not a management interface, but it does feature a running log of current events:
Conclusion
Working on Beeswarm was an amazing experience. If I had to make a list of new things that I learnt during this time, I'm pretty sure it would fill up a wall.
I want to thank my mentor, Johnny Vestergaard, for this awesome learning experience. He pulled me out of a tight spot more often than I'd like to admit :-) . I also thank Lukas Rist, my backup mentor, for teaching me about Flask, Bootstrap, and web-frameworks in general. Without that excellent web-development session, I would probably still be trying to fix CSS and HTML on the Beekeeper Web-app. Thanks, The Honeynet Project, for accepting my GSoC application. Also, thanks to Google for paying me and giving me the opportunity to learn. These two things seldom occur simultaneously. Long live GSoC! :)